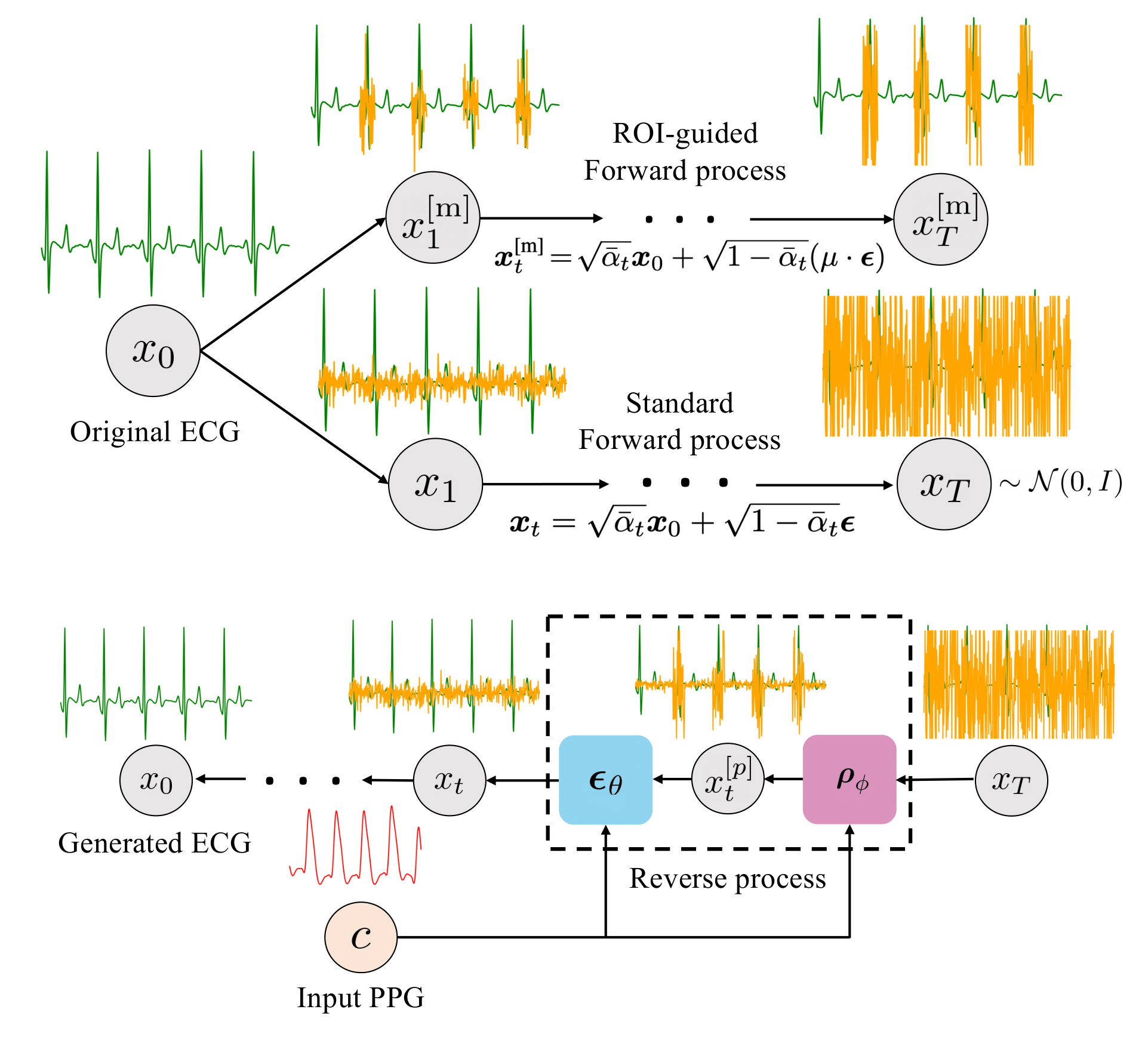
Region-Disentangled Diffusion Model for High-Fidelity PPG-to-ECG Translation
AAAI Conference on Artificial Intelligence, (AAAI), 2024.

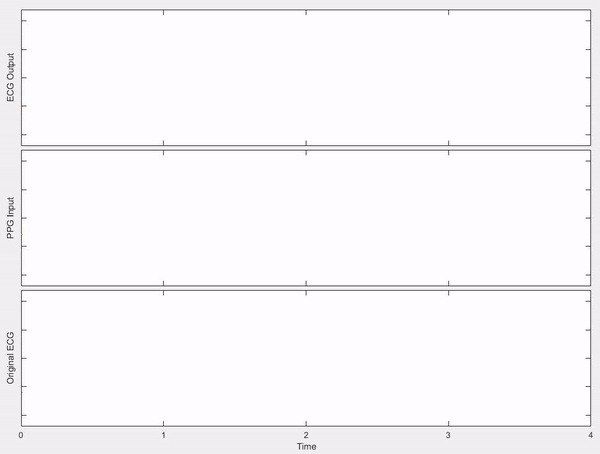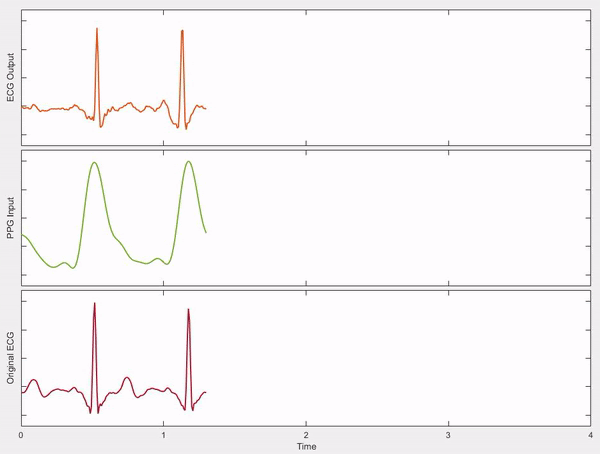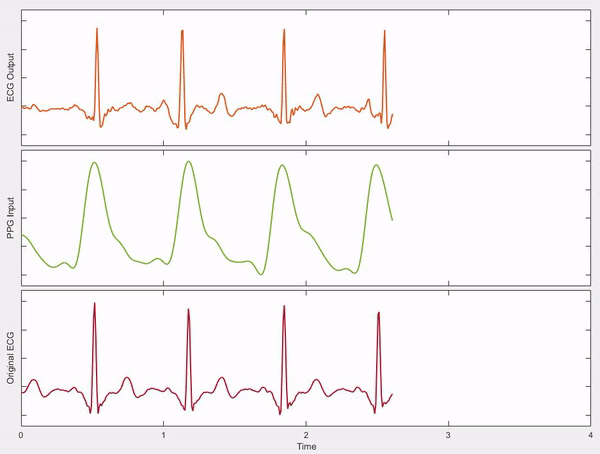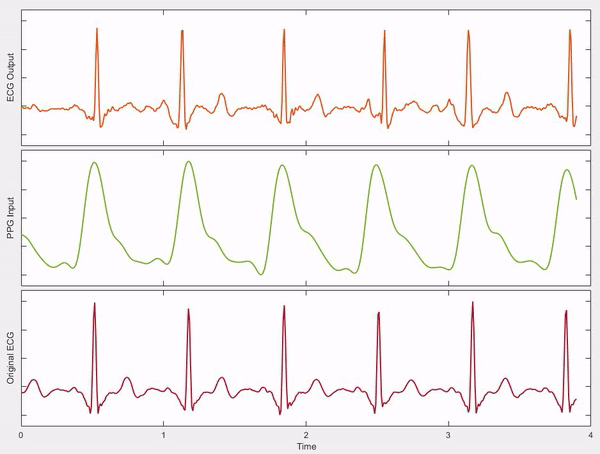

Happy Driver: Investigating the Effect of Mood on Preferred Style of Driving in Self-Driving Cars
International Conference on Human-Agent Interaction, (HAI), 2021.
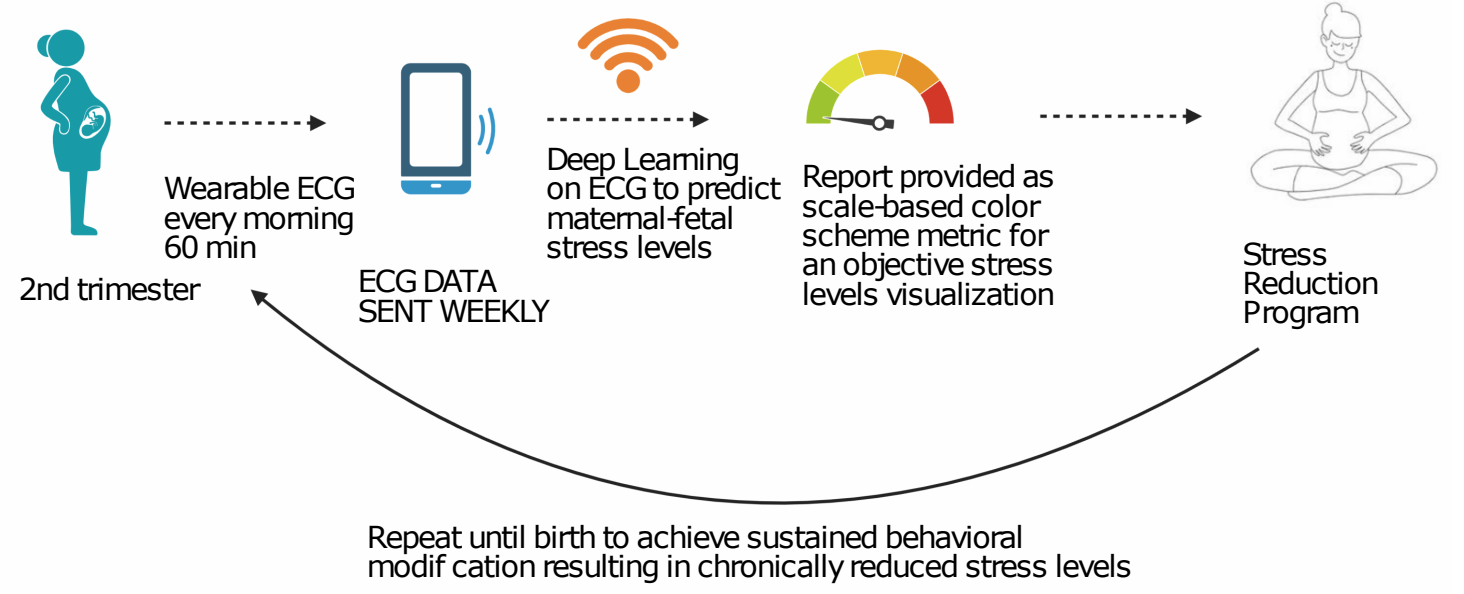
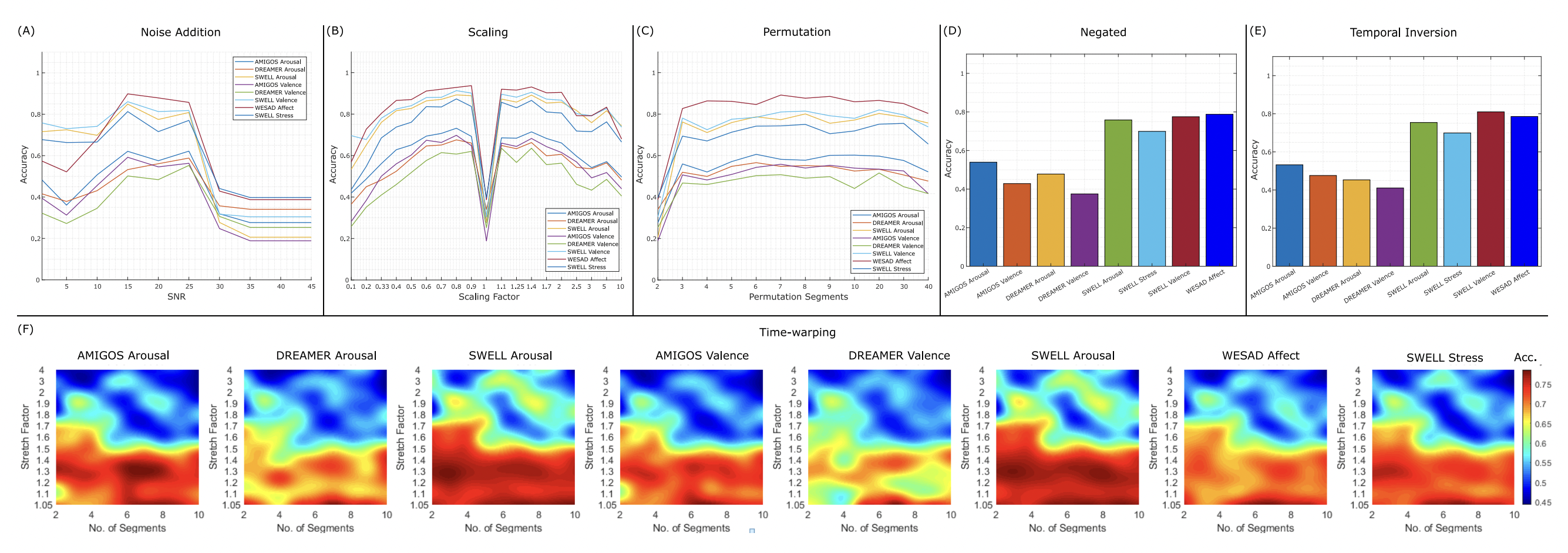
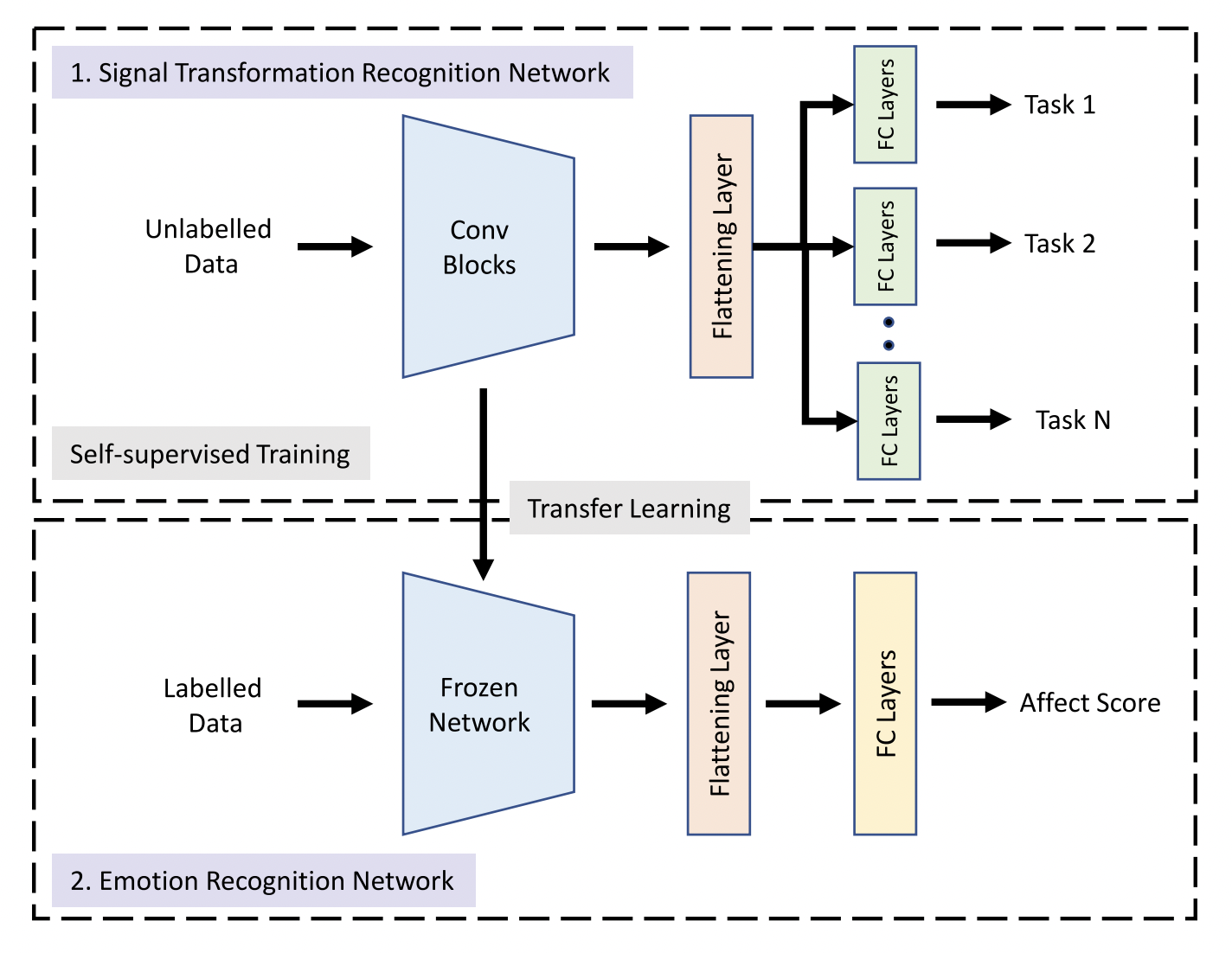
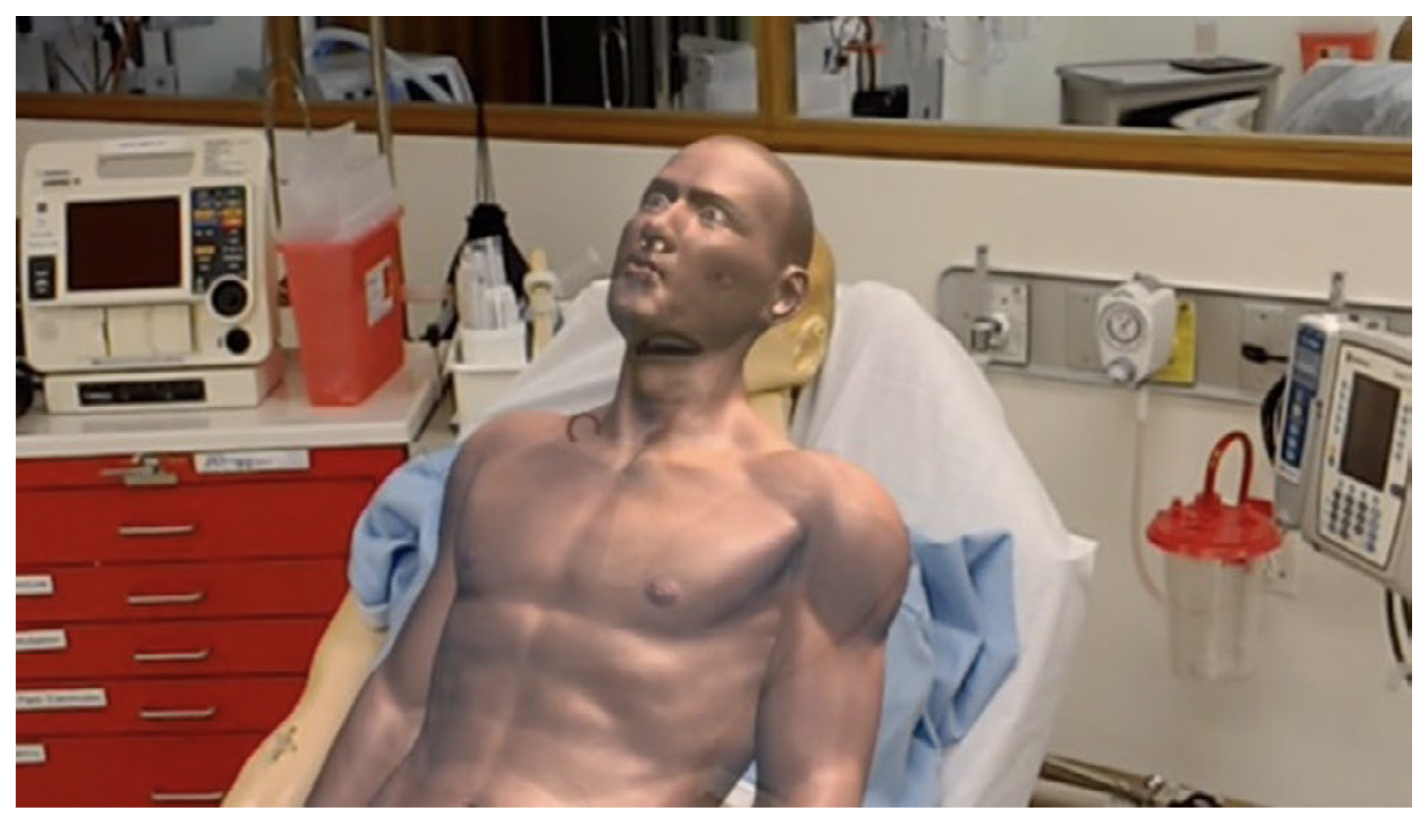
The Future of Simulation-based Medical Education: Adaptive Simulation Utilizing a Deep Multitask Neural Network
AEM Education and Training (AEMET), 2021.
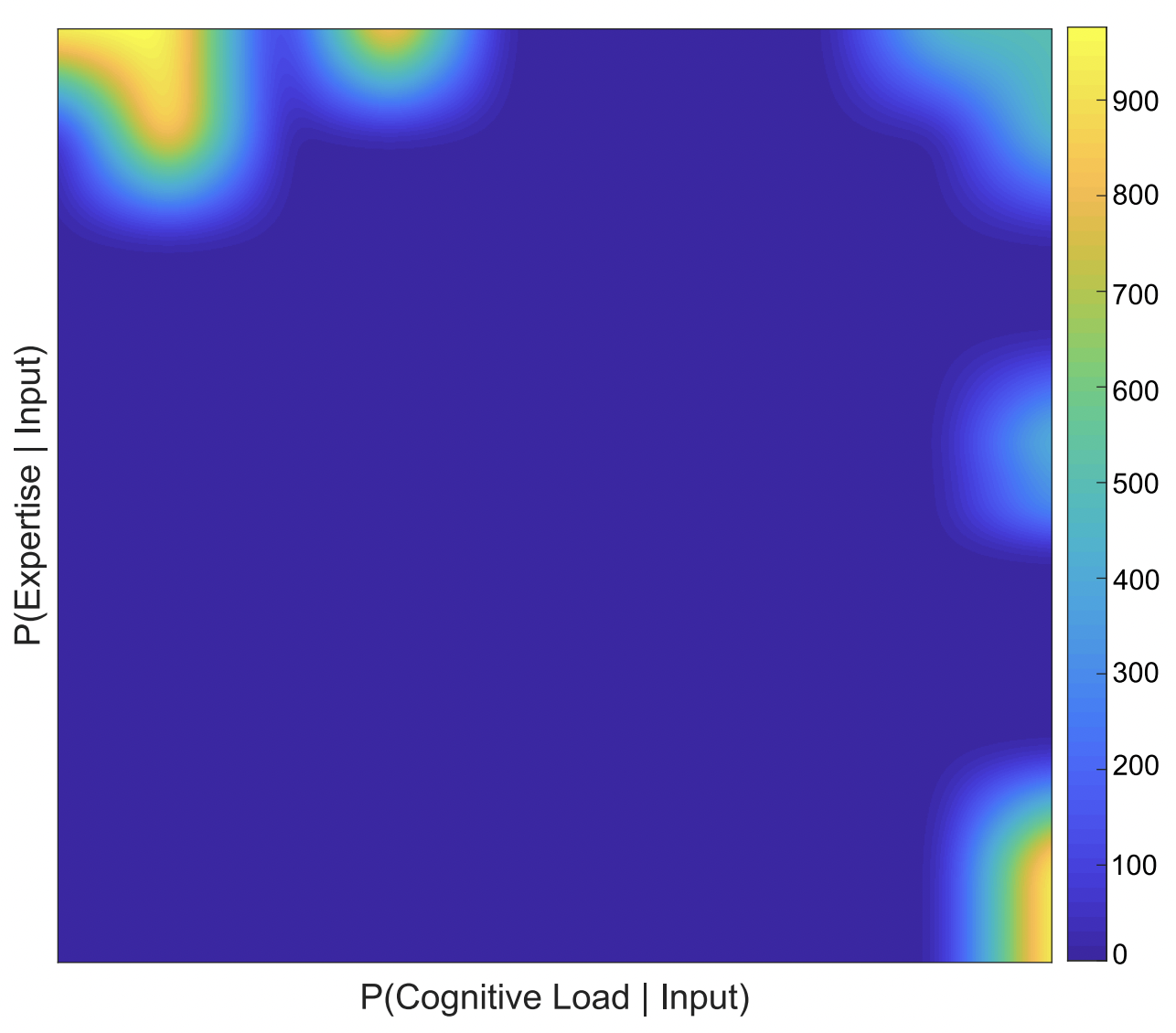
Classification of Cognitive Load and Expertise for Adaptive Simulation using Deep Multitask Learning
IEEE Affective Computing and Intelligent Interaction, (ACII), 2019. Oral
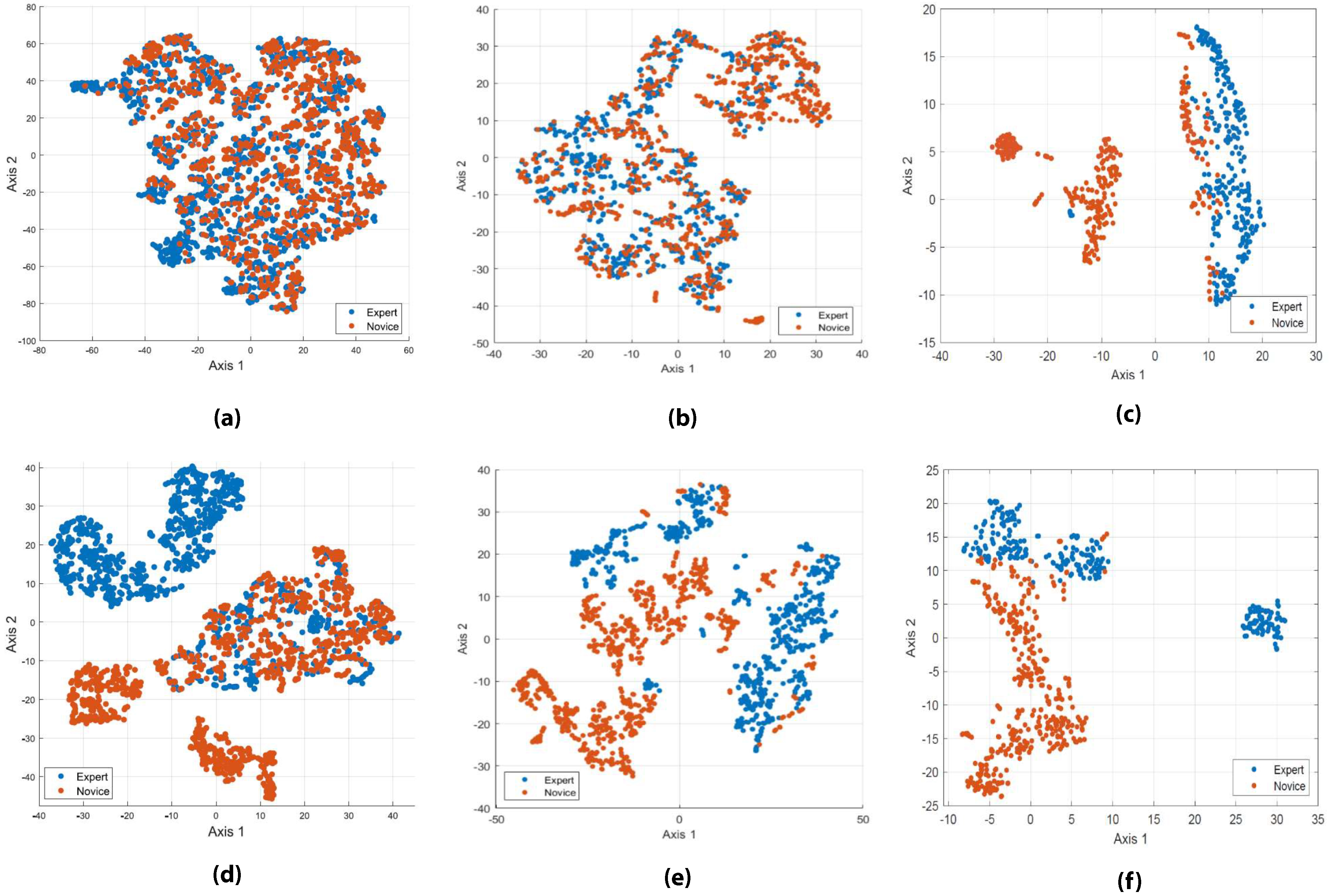
Toward Dynamically Adaptive Simulation: Multimodal Classification of User Expertise using Wearable Devices
Sensors, 2019
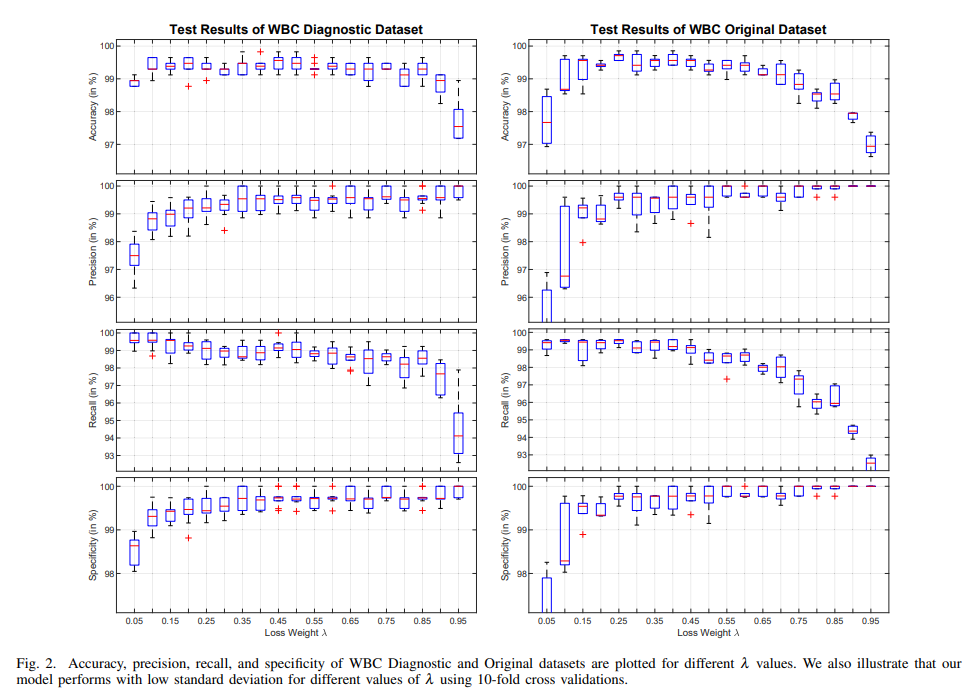
Computer-Aided Diagnosis using Class-Weighted Deep Neural Networks
IEEE International Conference on Machine Learning and Applications, (ICMLA), 2019.